Qwen_ImageEdit_2511
github地址:https://github.com/QwenLM/Qwen-Image
Qwen-Image-Edit-2511:阿里开源最强图像编辑模型深度解析
摘要:Qwen-Image-Edit-2511 是通义千问团队推出的最新开源图像编辑模型。相比传统扩散模型,它更专注于“基于文本指令修改图片”,在人物一致性、多图融合及工业级设计能力上表现卓越。
📌 简介
Qwen-Image-Edit-2511 是阿里通义千问团队推出的一个开源图像编辑模型,属于 Qwen-Image 系列中的“编辑(Image Editing)”版本。它的核心定位非常明确:专注于基于文本指令修改图片。
👉 简单理解:它 = “比 Stable Diffusion 更擅长改图、而不是单纯生成图”的模型。
🧠 一、核心能力
1️⃣ 高一致性编辑(最大亮点)
大幅减少“改着改着变脸/变人”的问题(image drift)。
- 单人一致性:换衣服、换姿势,仍是同一个人。
- 多人一致性:合照中人物面部不乱。
2️⃣ 多图输入 + 融合编辑
支持输入多张图片进行生成:
- 合成场景
- 人物融合(例如把两个人放进同一张图)
3️⃣ 内置 LoRA(开箱即用)
集成社区热门 LoRA,无需额外训练即可实现:
- 光影变化
- 视角变化
- 风格增强
4️⃣ 工业级设计能力
支持产品外观修改、材质替换及批量设计任务。
💡 注意:这点是很多开源模型不具备的,它更偏向于生产工具。
5️⃣ 几何与结构理解更强
能画辅助线 / 结构线,更适合:
- 设计图
- 工程草图
- UI/工业设计
⚙️ 二、技术特点
- 模型架构:基于 20B 参数 MMDiT(多模态扩散模型)。
- 工作原理:多模态理解(图 + 文本)+ 扩散生成。
- 生态支持:
- 支持
Diffusers(HuggingFace) - 支持多种加速框架 (
vLLM,LightX等)
- 支持
🚀 三、相比旧版本(2509)的提升
主要改进集中在以下五个维度:
- ✅ 人物一致性更好
- ✅ 多人场景更稳定
- ✅ 减少编辑漂移
- ✅ 支持更多创意效果(内置 LoRA)
- ✅ 推理能力更强(理解复杂指令)
🧩 四、典型应用场景
- AI 修图 / 换装 / 换背景
- 电商图片编辑
- 游戏/影视角色一致性生成
- 工业设计 & 产品建模
- 多图融合创作
💻 五、简单代码示例(核心思路)
from diffusers import QwenImageEditPlusPipeline
# 加载模型
pipe = QwenImageEditPlusPipeline.from_pretrained("Qwen/Qwen-Image-Edit-2511")
# 执行编辑
output = pipe(
image=[input_image],
prompt="让这个人穿上西装并站在办公室里"
)
👉 输入:图片 + 文本
👉 输出:编辑后的图片
🧭 总结一句话
Qwen-Image-Edit-2511 = 当前开源里“最强调一致性和可控编辑”的图像编辑模型之一
相比传统扩散模型,它更像一个:“可理解指令的 Photoshop AI”。
懒人包使用
点金启动脚本.bat
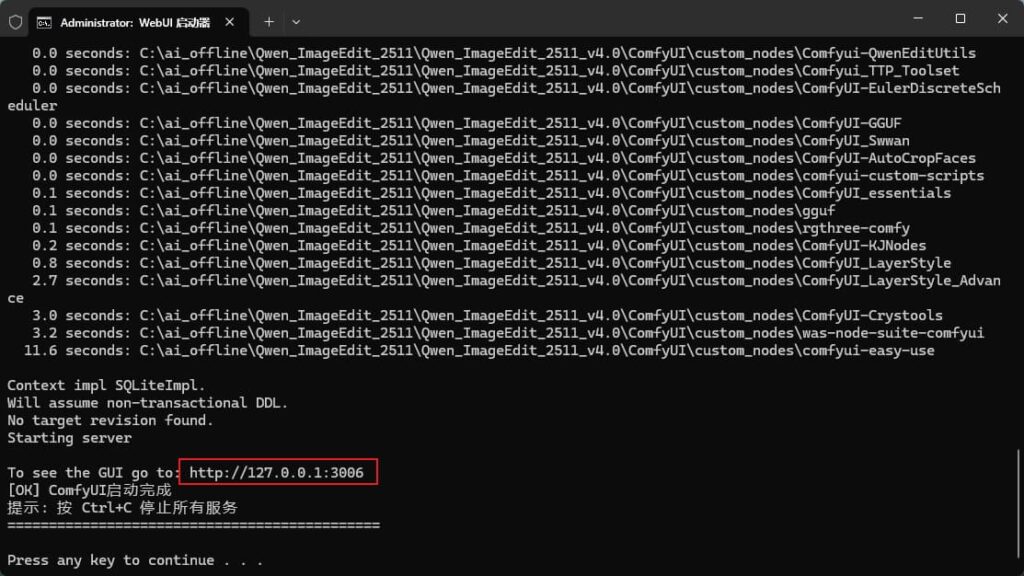
等待终端加载完成
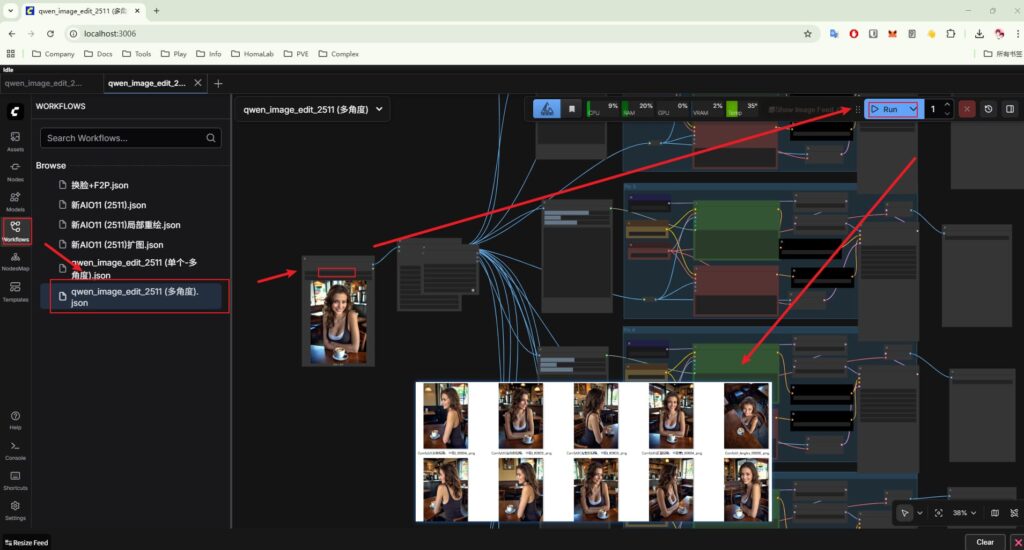
打开网址,点击workflows,双击多角度工作流
上传你自己的图片,点击run,可以获取预设值的8个角度图片
也可以自己添加或者修改角度
Tips
点击此处 网盘下载
适合用来画画,漫剧分镜等
1,304字