whisperx
github地址:https://github.com/m-bain/whisperx
🎙️ WhisperX:高精度、高效率的开源 ASR 工具详解
WhisperX 是在 OpenAI 语音识别模型 Whisper 基础上改进的开源自动语音识别(ASR)工具。它通过工程与算法优化,致力于实现更高精度和更高效率的语音转文字(Speech-to-Text),特别适合生产级应用。
📖 一、WhisperX 是什么?
简单来说:
WhisperX = Whisper + 对齐优化 + 说话人分离 + 加速
它是为了解决原始 Whisper 在以下场景的不足而设计的:
- ❌ 时间戳不精确(仅句子级)
- ❌ 长音频容易漂移
- ❌ 无法区分说话人
- ❌ 推理速度较慢
WhisperX 通过一系列优化,使其成为更适合生产级语音转录的强力工具。
🚀 二、核心功能亮点
1️⃣ 词级时间戳(最大亮点)
- 对比:Whisper 通常只提供句子级时间;WhisperX 精确到每个单词。
- 实现原理:强制音素对齐(Forced Alignment)+ wav2vec2 等模型辅助。
- 精度:可达 ±50ms 级别。
2️⃣ 说话人分离 (Speaker Diarization)
- 功能:精准识别“谁在说话”。
- 适用场景:会议记录、播客、面试分析。
- 技术实现:基于类似
pyannote的说话人嵌入(Speaker Embedding)技术。
3️⃣ 高速转录
- 性能:支持批量推理,速度可达 几十倍实时速度 (~70x)。
- 效率示例:1 小时音频 → 仅需几分钟即可处理完毕。
4️⃣ 长音频优化
- 适用对象:长视频、会议录音、直播回放。
- 优化手段:
- 利用 VAD(语音活动检测) 自动切分音频。
- 有效避免重复转录和“幻觉”问题。
5️⃣ 多语言与翻译支持
- 继承能力:完美支持中文、英文、日文等多语言。
- 扩展功能:支持
Speech → Text → Translation的全流程翻译。
⚙️ 三、技术原理(简化版)
WhisperX 的处理流水线如下:
graph LR
A[原始音频] --> B(VAD 切分/去静音)
B --> C(Whisper 初步转录)
C --> D{强制对齐}
D --> E(词级时间戳生成)
F[说话人分离模块] --> G(区分说话人身份)
E & G --> H[最终输出结果]
关键组件解析:
- Whisper: 负责初步转录。
- VAD: 去除静音片段,优化切分。
- Forced Alignment: 将文本与音频波形精确对齐。
- Speaker Embedding: 区分不同说话人身份。
⚖️ 四、Whisper vs. WhisperX
| 能力维度 | Whisper (原版) | WhisperX (优化版) |
|---|---|---|
| 时间戳精度 | 句子级 | ✅ 词级(极高精度) |
| 说话人识别 | ❌ 不支持 | ✅ 支持 |
| 长音频表现 | ⚠️ 一般,易漂移 | ✅ 优化良好 |
| 推理速度 | 🐢 较慢 | 🚀 极快 (约 70x) |
💡 一句话总结:WhisperX 是“工程强化版”的 Whisper。
🎯 五、典型应用场景
- 🎬 字幕生成
- YouTube / B 站视频字幕,精确到单词时间轴。
- 🧑💼 会议记录
- 自动区分发言人,生成结构化文本摘要。
- 🎙️ 播客/访谈分析
- 内容检索:快速定位“谁说了什么”。
- 📊 AI 数据处理
- 语音数据标注、NLP 训练数据生成。
✅❌ 六、优缺点总结
| ✅ 优点 | ❌ 缺点 |
|---|---|
| 时间戳极其准确(词级) | Pipeline 复杂,组件较多 |
| 支持说话人分离 | 部署依赖较重(强烈建议 GPU) |
| 速度极快 | 对齐步骤需要额外加载模型 |
| 开源、可本地部署 |
🏁 七、结语
👉 WhisperX 是目前做“高精度字幕 + 多人语音转写”的最佳开源方案之一
懒人包使用
双击start.bat
等待终端启动
访问http://localhost:7860/
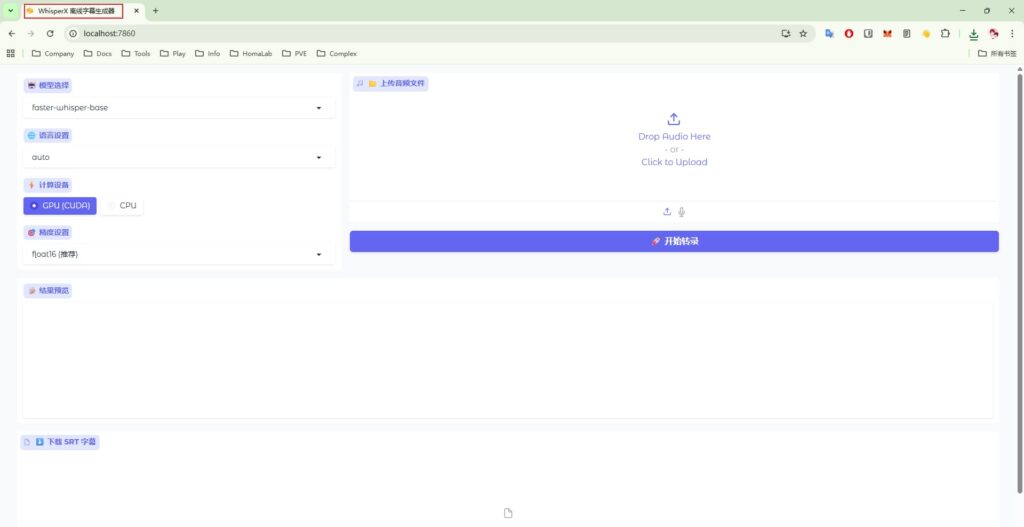
和之前的fast whisper一样的界面,选择模型,选择gpu,上传音频,点击转录
只不过底层改为whisperx
Tips
点击此处 网盘下载
注意,本文whisperx,仍然无法实现双语字幕,或者日文转中文字幕,英文转中文字幕
还是只能原来的音频是什么语言,字幕就是什么语言
只是相对来说字幕的时间轴更加精准
可以同时识别不同人的(打上标签)(这个功能没做,暂时用不着)
所以相当于fast whisper的进阶版本

1,620字