Qwen3-ASR
github地址:https://github.com/QwenLM/Qwen3-ASR
🎙️ Qwen3‑ASR 模型选型指南:0.6B vs 1.7B
基于官方技术报告与社区 Benchmark 整理
旨在帮助开发者根据业务场景(速度/成本 vs 精度/鲁棒性)选择最合适的语音识别模型。
📌 1. 基本定位与目标
| 特性 | Qwen3‑ASR‑0.6B | Qwen3‑ASR‑1.7B |
|---|---|---|
| 参数量级 | ~0.6 Billion | ~1.7 Billion |
| 核心定位 | 高效、低延迟、高并发 | SOTA 级别准确率、强鲁棒性 |
| 适用场景 | 对性能/速度要求极高的实时场景 | 复杂语言环境、噪声环境下的精准识别 |
🧠 2. 识别质量对比(准确率 & 鲁棒性)
🔹 Qwen3‑ASR‑1.7B:更强的识别能力
- 基准表现:在官方评估及公开 Benchmark(Fleurs, MLS, CommonVoice 等多语种数据集)中,错误率显著低于 0.6B。
- 抗噪与泛化:对噪声、方言、复杂语境(如歌唱、背景音乐)具有极强的鲁棒性。
- 结论:在长语音、低资源语言及高难度场景下表现卓越。
🔹 Qwen3‑ASR‑0.6B:精度依然可靠
- 基准表现:虽略逊于 1.7B,但在常见任务上错误率仍优于多数开源 Baseline(如 Qwen3‑Flash)。
- 适用性:对于标准短句或中等难度语音,能提供可靠的识别结果。
💡 准确性总结:1.7B > 0.6B。差异在长语音、低资源语言及噪声场景下尤为明显。
⚡ 3. 性能 & 资源消耗对比
| 指标维度 | 🟢 Qwen3‑ASR‑0.6B | 🔵 Qwen3‑ASR‑1.7B |
|---|---|---|
| 推理速度 / 延迟 | ⚡ 极快 首字响应约 ~92ms,低延迟 | 🐢 相对较慢 计算密集,延迟较高 |
| 吞吐量 / 并发 | 📈 优秀 128 并发下可维持极高吞吐 | ⚖️ 中等 不如 0.6B 适合高并发场景 |
| 显存占用 | 💰 更低 适合弱硬件/边缘设备部署 | 📦 更高 需要更强的算力支持 |
💡 性能总结:0.6B 胜在低延迟与边缘部署;1.7B 胜在准确性,适合服务器/云端高算力环境。
🌍 4. 多语种与能力支持
两者均基于统一架构,共享以下核心能力:
- ✅ 语言覆盖:支持约 52 种 语言和方言的识别 + 多语种 ASR。
- ✅ 推理模式:支持在线/流式推理 & 离线长音频识别。
- ✅ 环境适应:具备对抗噪声、口音及不同语速的能力。
差异化优势:
- 🏆 1.7B:在多语种性能上更稳定,尤其在少数资源语言和高复杂度输入下错误率更低。
- ⚡ 0.6B:在实时性与并发处理上占优,是边缘部署与批量转录的首选。
🧩 5. 典型使用场景建议
🟢 选择 Qwen3‑ASR‑0.6B
“效率优先”方案
- ✅ 追求极致速度:低延迟、高并发吞吐量需求。
- ✅ 资源受限:部署在显存小的设备、嵌入式/边缘场景或本地推理。
- ✅ 成本敏感:需要更低算力成本运行,对极端准确率要求适中即可。
🔵 选择 Qwen3‑ASR‑1.7B
“精度优先”方案
- ✅ 追求最高质量:需要 SOTA 级别的识别准确率。
- ✅ 复杂环境:处理嘈杂背景、方言口音或超长音频。
- ✅ 生产级应用:用于高质量字幕生成、研究或核心 ASR 服务。
- ✅ 算力充足:不介意更高的显存与算力开销,部署于高性能服务器。
📊 6. 优缺点速览表
| 对比维度 | Qwen3‑ASR‑0.6B | Qwen3‑ASR‑1.7B |
|---|---|---|
| 准确率 | ⭐⭐⭐ (中等偏上) | ⭐⭐⭐⭐⭐ (SOTA 水平) |
| 推理速度 | 🚀 更快 | 🐢 稍慢 |
| 硬件需求 | 💾 更低 (边缘友好) | 🖥️ 更高 (服务器友好) |
| 复杂场景表现 | 👍 良好 | ⭐⭐⭐⭐⭐ 更佳 |
| 部署范围 | 🌍 更广 (含移动端/IoT) | 🏢 高性能中心/云端 |
💬 一句话总结
Qwen3‑ASR‑0.6B 是效率优先的轻量级选择,适合边缘与实时场景;
Qwen3‑ASR‑1.7B 是准确率优先的高性能选择,专为复杂环境与质量敏感型应用而生。懒人包使用
双击start1.7B.bat
等待终端启动
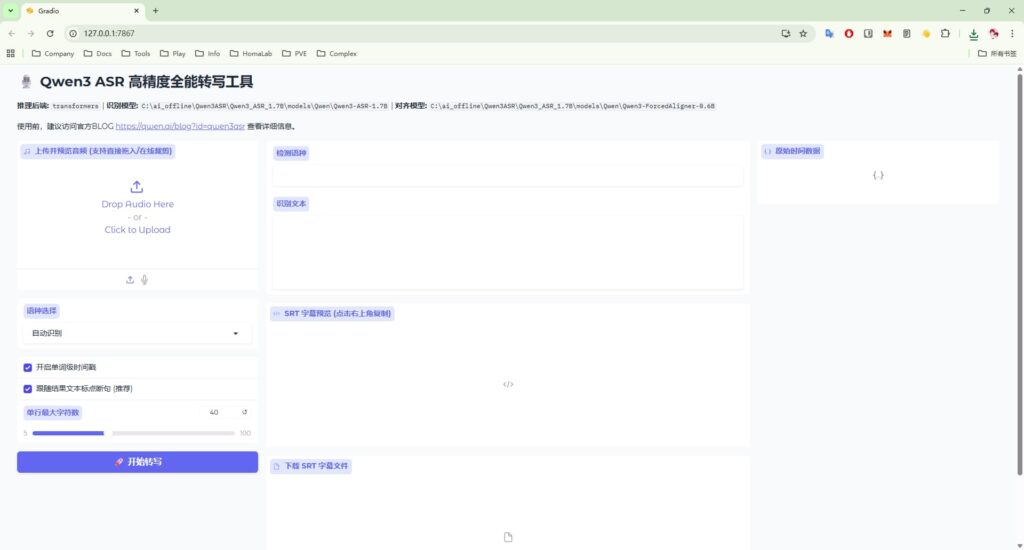
访问http://127.0.0.1:7867/
上传音频,点击转录
Tips
点击此处 网盘下载
昨天设置了Qwen3-ASR 0.6B版本
今天添加Qwen3-ASR 1.7B版本,适合8-12GB显存使用
特别说明,本文懒人包基准仅为自己的电脑win11和3060 12GB显卡
其他如A,I卡,和50系N卡等,都不在兼容适配系列,其他的理论上可用,建议cuda版本在12.8及以上
1,655字