前言
上一期内容记录了paddleocr PP-StructureV3 pdf转md 懒人整合包 cpu可用
本文主要是记录把paddleocr PP-StructureV3 pdf转md 懒人包改为gpu可用
毕竟cpu用来体验效果还行,但是批量或者重度用户,最求速度还是优先考虑使用gpu,不能让gpu闲置
其他的功能并没有更新
承接上一期内容,发布了基于 PaddleOCR PP-StructureV3 的 PDF 转 MD 懒人整合包 CPU 版。在收到大量反馈后,发现虽然 CPU 版适合轻量级体验和临时使用,但对于批量处理、重度用户或追求极致效率的场景,CPU 的算力瓶颈逐渐显现。 本期文章主要记录如何将 PaddleOCR PP-StructureV3 懒人包升级为 GPU 加速可用版本。毕竟显卡闲置是资源的浪费,对于需要快速出结果的用户来说,优先使用 GPU 加速是更优解。其他核心功能逻辑保持不变,重点在于底层推理引擎的切换与性能优化。
环境要求与硬件适配
GPU 版的核心差异在于对显卡算力的调用。
- CUDA 版本:本懒人包基于
cuda11.8编译,请确保你的电脑已安装对应版本的 CUDA Toolkit(或依赖包内自带)。 - 显卡支持:目前主要适配 NVIDIA RTX 3060 及以上型号。暂未适配最新的 50 系 N 卡,原因是驱动版本与算子兼容性尚需验证,建议 40/30 系用户优先使用。
- 显存要求:模型加载约占用 2.4GB 显存,处理复杂 PDF 时峰值可达 6GB 左右。如果你的显卡显存低于 4GB(如部分笔记本独显),可能会在批量处理时出现 OOM(显存溢出)报错,建议优先使用 CPU 版。
懒人包使用说明
- 启动方式:双击
start.bat,无需手动配置 Python 环境或 pip install。 - 加载过程:终端会显示 CUDA 初始化进度,等待提示“服务已启动”后,浏览器会自动跳转至
http://localhost:7860/。 - 界面交互:与 CPU 版一致,左侧上传 PDF/PNG,右侧实时预览 MD 结构。
- 性能差异:在相同硬件环境下,GPU 版的处理速度通常比 CPU 快 5-10 倍。特别是对于包含大量表格或复杂排版的 PDF,GPU 能显著降低等待焦虑。
避坑指南(Tips)
- 端口占用:如果启动后浏览器未自动打开,检查终端是否有
Port 7860 occupied提示,可尝试关闭其他占用端口的程序。 - 显存不足:若处理大文件时闪退,请尝试在设置中减少并发数或切换回 CPU 模式(后续版本将增加一键切换开关)。
- 模型加载:首次启动需加载约 2.4GB 的本地模型文件,请耐心等待。
性能实测数据
为了让大家更直观地感受差异,我们进行了简单测试:
- CPU 版:处理一份 10 页含表格的 PDF,耗时约 3-5 分钟,且风扇噪音较大。
- GPU 版:同样文件,耗时压缩至 20-40 秒,显卡负载平稳。
- 显存监控:启动后显存占用稳定在 2.4GB,处理过程中峰值约 6GB,适合主流游戏本及台式机。
后续计划与下载
目前的 GPU 版主要聚焦于 PP-StructureV3 的加速,后续的 PaddleOCR vL1.5 等模型也将逐步适配 GPU 版本。
懒人包使用
gpu懒人包多了一个显卡检测,主要使用cuda11.8
暂未适配50系N卡,依旧只测试了3060显卡
双击start.bat
等待终端正常启动
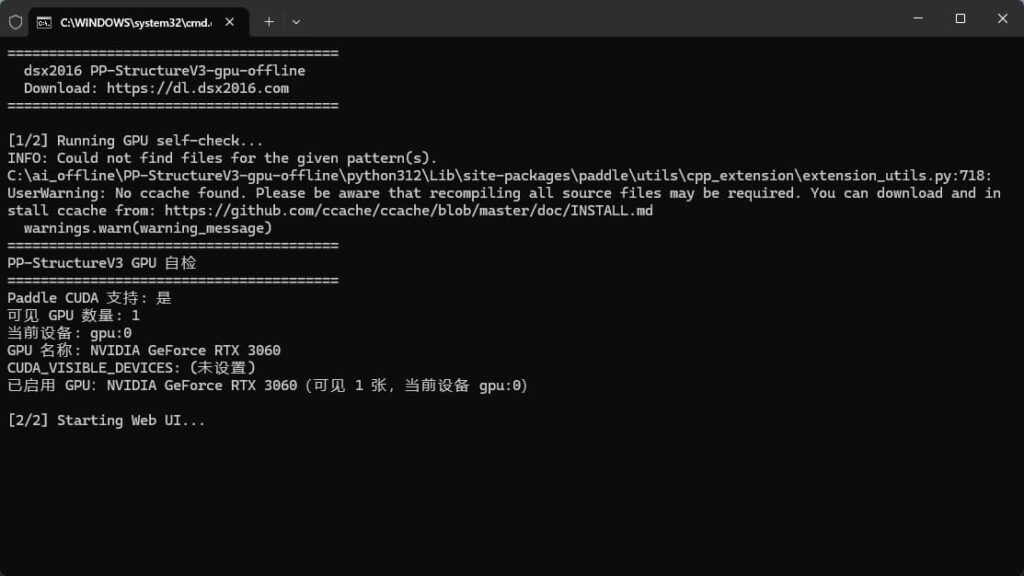
加载成功,会自动打开浏览器 http://localhost:7860/
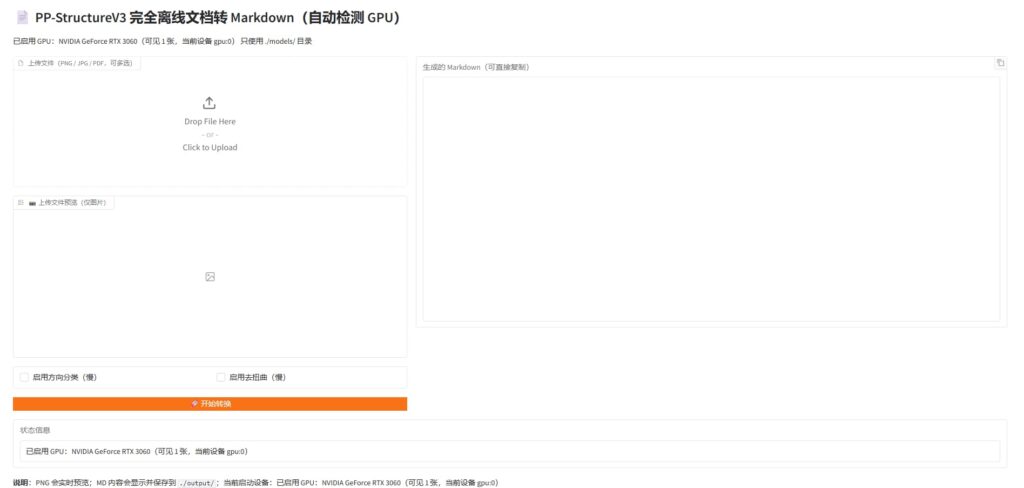
左侧上传图片或者PDF,右侧输出内容结果,或者查看output文件夹查看文件
使用界面如图
Tips
点击此处 网盘下载
实测加载模型大约2.4GB显存
测试PDF和图片转MD后,显存达到6GB左右
懒人包网盘文件一般会在视频和文档发布后才会上传,大概需要等3-12小时才会有(也就是一般第二天的早上),所以如果下载地址没有更新,就需要等待一些时间