Qwen 3.5
最近Qwen 3.5本地大模型刚出一段时间,正好测试一下这几天刚出的27B和35B-a3B模型
首先,软件使用Ollama客户端,记得一定要升级到最新版本,否则会提示当前版本不支持Qwen 3.5
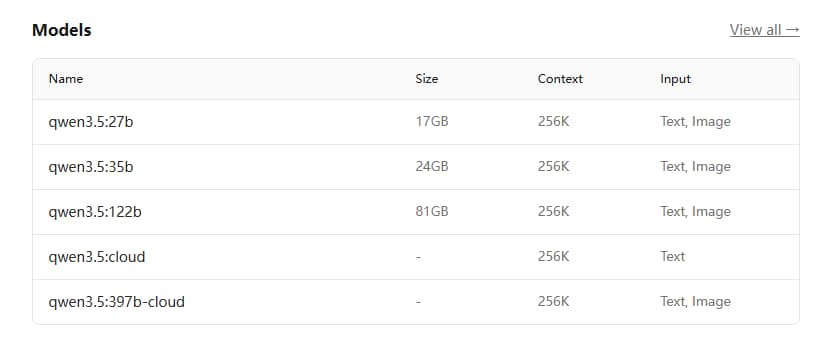
ollama Qwen 3.5 模型地址
https://ollama.com/library/qwen3.5
显存比较小的,建议下载q4量化模型qwen3.5:27b-q4_K_M和qwen3.5:35b-a3b-q4_K_M
注意本文只是尝鲜测试,实际显存12Gb,测试速度预期会很慢
并且Ollama客户端没有token速度数据,只能用其他方式或者查看文字速度来描述token速度是否流畅
在我的电脑上qwen3.5:27b-q4_K_M,第一次交互很慢,第二次直接报错500
qwen3.5:35b-a3b-q4_K_M速度也很慢,几乎不能接受,但是第二次交互不会报错,有耐心的话可以一直对话,但是没必要,等待时间很长,建议显存至少24GB或者进行其他方式的优化
理论上我的3060 12GB的显存,qweb3:8B基本流畅,再往上14B就开始卡顿,不太试用了
openclaw
最近小龙虾的热度依旧居高不下
为了体验一下它的作用和操作,我打算使用Ollama本地大模型,简单的执行一个小任务
第一个想法就是让openclaw打开chrome浏览器,然后打开一个天气预报的网页,分析并汇总当前天气数据,然后发消息给我
然后我把这个过程再度简化为让打开chrome浏览器,然后打开网页百度,就算成功

使用官网的命令在powerShell安装了openclaw
然后在Ollama客户端安装了glm-4.7-flash:q4_K_M的本地大模型
然后使用ollama启动openclaw,给它一个命令执行
首先让它打开浏览器和打开网页失败了,它回复需要设置chrome扩展
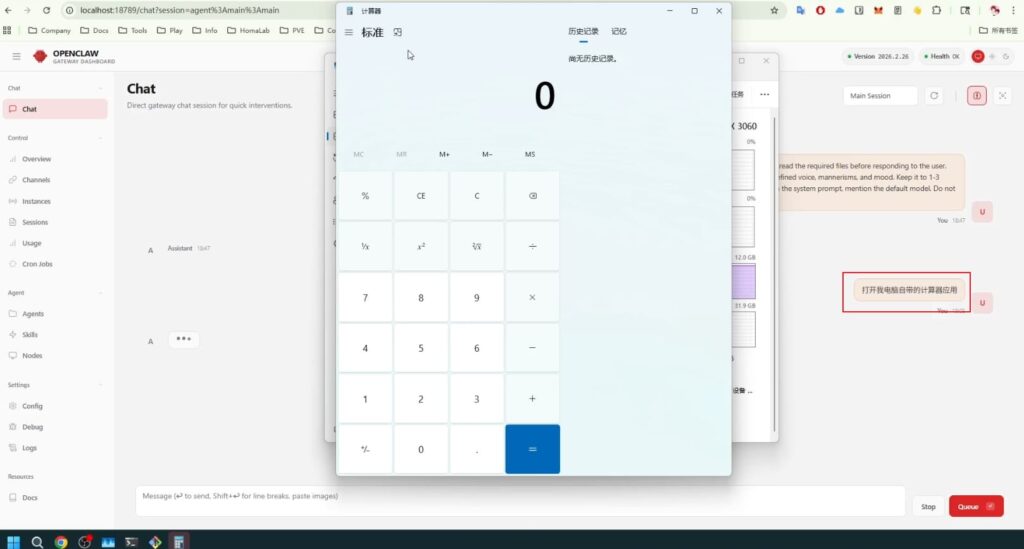
于是我改为让它打开电脑的系统应用:计算器
在等待10分钟,cpu,gpu和内存几乎爆满的情况下,还是完成了打开系统计算器的任务
Tips
要使用本地大模型,建议24Gb显存及以上,其他低显存尝试一下就好,优先考虑云ai token
openClaw在window上一行命令安装成功,也一行命令就ollama结合openclaw来执行简单任务,使用本地大模型
轻量的任务打开软件没有问题,复杂的流程仍然需要云端token
目前qweb3.5最新的相对小的模型为27B,显存足够可以尝试一下,27B和35B在本地大模型中,属于基本可用状态,用豆包的概括来说,属于大学生水平,处于chatgpt初入付费那一档