faster-whisper
github地址:https://github.com/SYSTRAN/faster-whisper
🚀 Faster-Whisper:Whisper 的高性能工业级推理引擎
1️⃣ 项目简介
Faster-Whisper 是由 SYSTRAN 开源的语音识别库,它是 OpenAI Whisper 的高性能重实现。
💡 核心思路:用 CTranslate2 替换原始推理框架,在保持精度的同时,让 Whisper 跑得更快、更省资源。
2️⃣ 痛点与解决方案
❌ 原版 Whisper 的局限
- 🐢 推理速度慢
- 💾 显存/内存占用高
- 🖥️ CPU 性能表现一般
✅ Faster-Whisper 的目标
| 特性 | 优化效果 |
|---|---|
| ⚡ 速度 | 显著加速推理过程 |
| 💾 资源 | 极致降低内存/显存占用 |
| 🏠 部署 | 完美适配本地环境(CPU/GPU) |
3️⃣ 核心优势深度解析
🔥 1. 性能飞跃
- 速度提升:在同等精度下,最高可达 4 倍 的速度提升。
- 批处理支持:原生支持 Batching,大幅提升吞吐量。
- 硬件适配:对 GPU 和 CPU 均进行了深度优化。
📊 实测对比(13 分钟音频转录)
- 🐢 原版 Whisper:约 2 分 23 秒
- ⚡ Faster-Whisper:约 1 分 03 秒 (甚至更快)
💾 2. 资源优化
- 低显存占用:显著减少内存峰值。
- 量化支持:原生支持 INT8 量化,进一步降低资源消耗。
- 全平台兼容:CPU / GPU 均可高效运行。
🛠️ 3. 工程化友好
- API 简洁:Python API 设计直观,上手极快。
- 功能丰富:
- ✅ 批量转录
- ✅ 多语言识别
- ✅ Word-level 时间戳
- ✅ VAD(语音活动检测)
🔗 4. 生态兼容
- 模型通用:支持
tiny,base,small,large等所有标准 Whisper 模型。 - 权重转换:无缝加载 HuggingFace / Whisper 官方权重。
- 输出一致:输出格式与原版保持高度一致,迁移成本几乎为零。
🧠 定位理解:它是 Whisper 的 “加速版推理后端”。
4️⃣ 典型应用场景
| 场景分类 | 具体应用 |
|---|---|
| 🧠 AI 应用开发 | 语音助手(本地输入)、会议自动记录、视频自动生成字幕 |
| 🖥️ 私有化部署 | 离线语音识别(无网可用)、数据隐私保护(不依赖云端) |
| ⚡ 实时/近实时 | 实时字幕生成、流式语音识别(结合其他工具) |
5️⃣ 快速上手 (Python)
仅需几行代码即可体验:
from faster_whisper import WhisperModel
# 初始化模型:使用 small 模型,CPU 运行,开启 INT8 量化
model = WhisperModel("small", device="cpu", compute_type="int8")
# 执行转录
segments, info = model.transcribe("audio.mp3")
# 输出结果
for segment in segments:
print(segment.text)
6️⃣ 横向对比:谁更合适?
| 实现方案 | 特点描述 | 适用场景 |
|---|---|---|
| OpenAI/Whisper (官方) | 准确度高,但推理慢、资源消耗大 | 追求极致精度,不计较速度 |
| whisper.cpp | C++ 实现,极度轻量,功能相对受限 | 嵌入式设备或极简环境 |
| transformers | 灵活度高,但性能表现一般 | 快速原型验证 |
| 🚀 Faster-Whisper | 速度与内存的最优平衡 | 生产环境、本地部署首选 |
💬 结论:在实际工程中,它是目前最常用的 Whisper 推理方案之一。
🏁 总结
Faster-Whisper = Whisper 的高性能工业级推理版本
- ⚡ 更快:推理速度显著提升
- 💾 更省:资源占用大幅降低
- 🏭 更稳:专为生产环境设计
懒人包使用
双击start.bat
等待终端启动成功
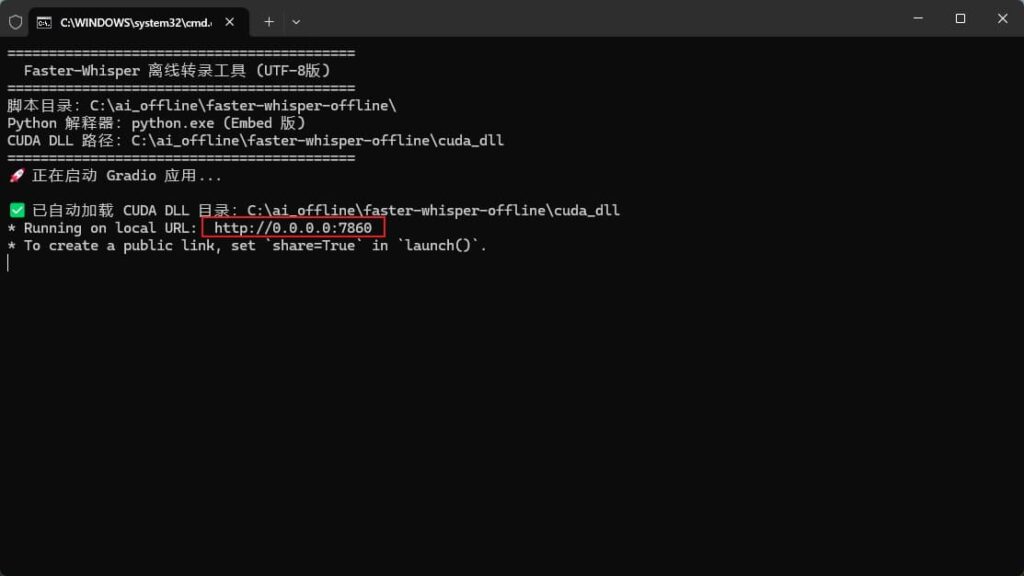
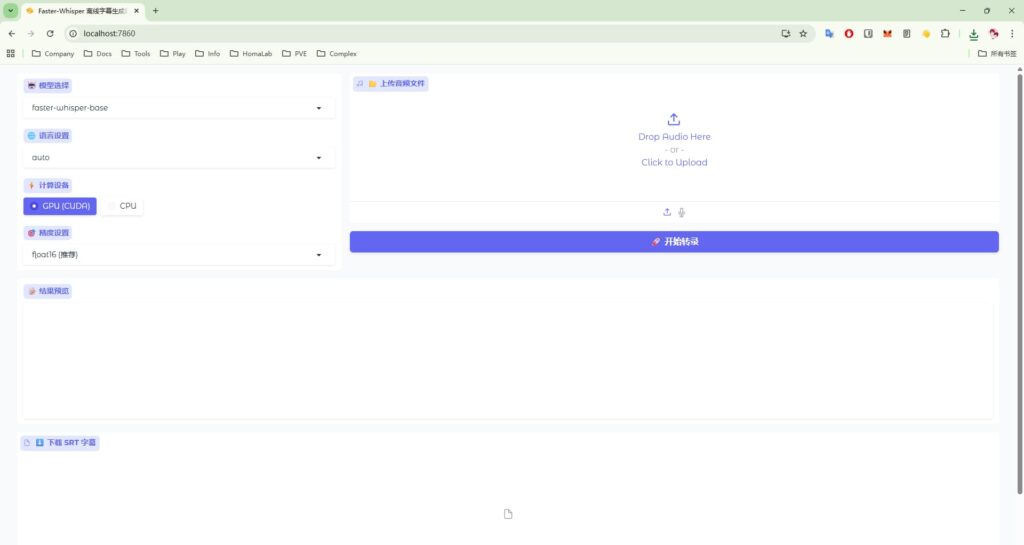
访问http://localhost:7860/
选择模型,上传音频,点击开始转录
转录成功后可以查看或者点击下载
Tips
点击此处 网盘下载
原以为Faster-Whisper速度快,且能够实现英转中或者双语字幕
懒人包制作完才发现各种报错,ai提示无法英文转中文,只能视频是什么语言就转什么语言的字幕
所以这个懒人包只有音频转字幕的功能,没有双语字幕或者转译的功能
后面再酌情查看可以双语字幕的ai懒人包
1,620字