fashn-vton-1.5
github地址:https://github.com/fashn-AI/fashn-vton-1.5
0️⃣ 项目定位:是什么?
fashn-vton-1.5 是一个开源的虚拟试衣模型,旨在提供生产级的高质量生成方案。
| 📥 输入 | 📤 输出 |
|---|---|
| 👤 人物照片<br>👕 服装图片 | ✨ “人穿衣”的真实感图像 |
- 核心定位:可用于生产环境的高质量开源方案。
- 适用场景:电商展示、试衣 App、内容创作等。
🚀 一、四大核心亮点
1️⃣ Pixel-space(像素空间生成)
解决痛点: 传统方法因压缩导致细节丢失。
| 对比项 | 传统 VTON (Latent Space) | fashn-vton-1.5 (Pixel Space) |
|---|---|---|
| 处理方式 | VAE 压缩 → Latent → 解码 | 直接在 RGB 像素空间生成 |
| 细节表现 | ❌ Logo/纹理易模糊 | ✅ 清晰、真实,接近电商效果 |
2️⃣ Maskless(无分割推理)
解决痛点: 传统方法依赖人体分割 Mask,边界易出错。
- 无需 Mask:完全不需要手动或模型生成的人体分割图。
- 自动学习:模型自动判断“哪里该换衣服”、“哪里保持不变”。
- 效果优势:
- 🧥 衣服形变更自然(如宽松衣物)。
- 👤 完美保留人体特征(脸、手等细节)。
3️⃣ 高性价比(非巨型模型)
定位: 垂直领域专用优化,而非盲目堆砌参数。
- ⚙️ 参数量:约 972M (接近 10 亿)
- 🖥️ 推理速度:H100 ≈ 5 秒/张
- 💾 显存需求:~8GB (消费级 GPU 即可运行)
4️⃣ 完全开源 + 可商用
关键意义: 摆脱闭源 API 依赖,直接落地产品。
- 📜 License:
Apache 2.0 - 📦 资源提供:
- ✅ HuggingFace 权重
- ✅ GitHub 推理代码
- 💰 商业友好:可直接用于电商或试衣 App 开发。
🧠 二、模型架构简述
核心架构:MMDiT (多模态扩散 Transformer)
- 双流交互:Person + Garment 分别编码,学习衣服如何匹配人体。
- 单流融合:统一生成最终图像。
- Patch-mixer:关键优化点,用于降低计算成本。
📝 输入数据包含
- 👤 人物图
- 👕 服装图
- 🗺️ 姿态 (keypoints)
- 🏷️ 类别 (上衣 / 下装 / 连衣裙)
💡 总结:为什么值得关注?
| 维度 | fashn-vton-1.5 优势 |
|---|---|
| 效果 | 像素级细节保留,纹理不糊 |
| 易用性 | 无需复杂预处理 (Maskless) |
| 成本 | 消费级显卡可跑,推理快 |
| 生态 | Apache 2.0 开源,可商用落地 |
🎯 一句话评价:这是一个在效果、速度与成本之间取得极佳平衡的垂直领域专用模型。
懒人包使用
双击start.bat,等待终端启动
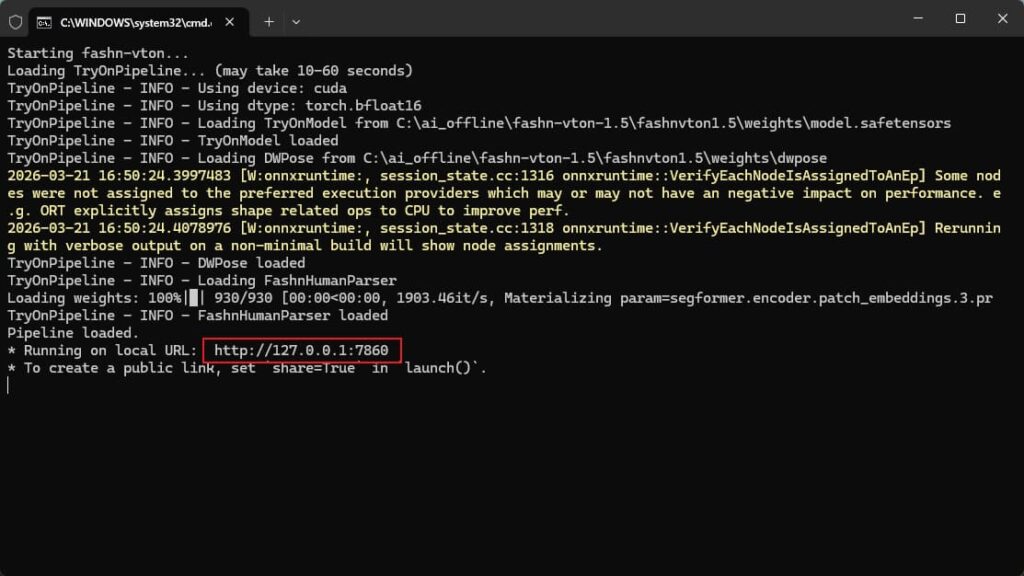
终端启动后,访问红框中的网址
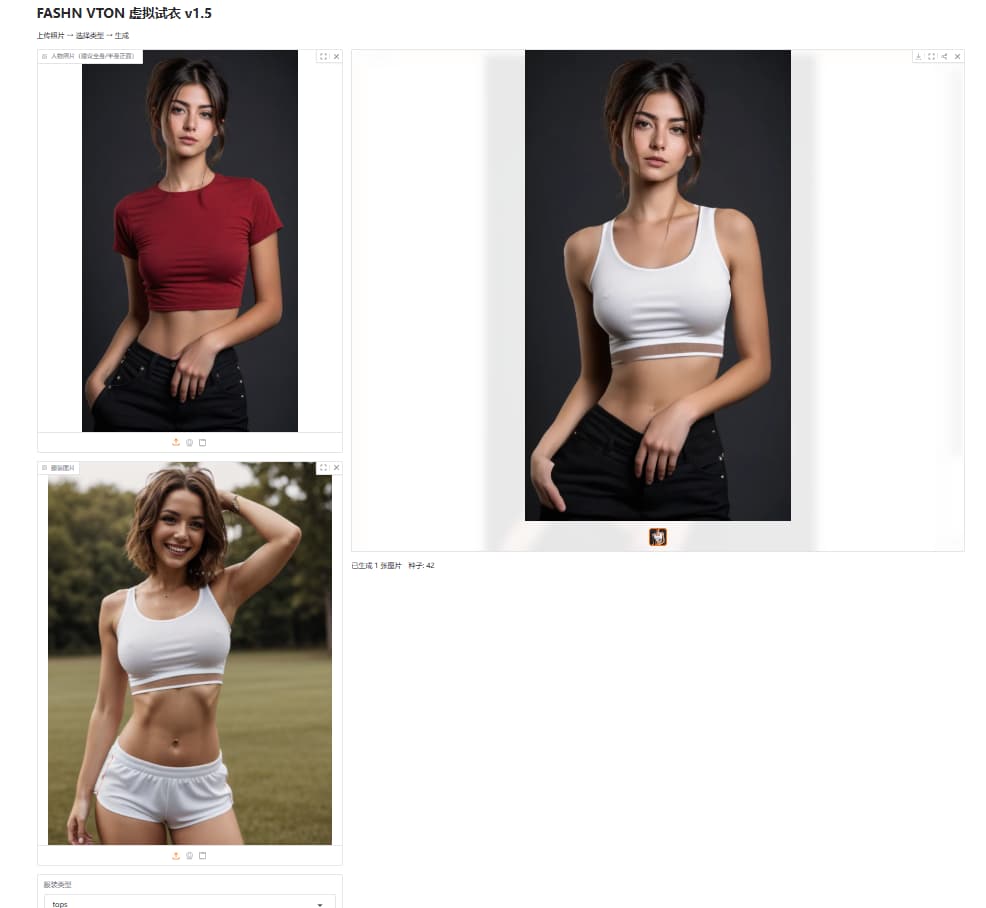
打开网址后,按照文字提示
上面选择目标人物,下面选择要换的衣物(或者参考衣物的人像)
选top替换上半身,选择bottom替换下半身,选择one替换全身(比如连衣裙等)
Tips
点击此处 网盘下载
这个模型只专注一键换衣,适合电商等使用场景
相比其他模型,有着更好的一致性
其他的模型优点在于可以无中生有,在原本的服装上修改颜色和样式等,但也同时是缺点
当我们只想测试衣物原本的效果时,不需要改变颜色,不需要改变细节,就可以使用这个效果
建议换装时,优先使用全身照片,正面照片,这样模型效果更好
1,252字