前言
从之前的fastapi转gradio界面,已经重新打包了3个左右的懒人包
核心是为了把编程api转为可视化操作交互网页,更加方便,同时也是为了重新优化项目结构,方便后续更改和优化,比如添加python依赖和添加其他界面功能
如果不重新制作懒人包结构,那么后面要做改动,会花费10倍的时间也达不到一个预期的效果,重新制作后,可能几分钟半小时就能大改版
现在fastapi的界面几乎没了,开始第二阶段,就是把之前网上整合的别人的懒人包,自己重新做,尤其是项目里面可能带有api的
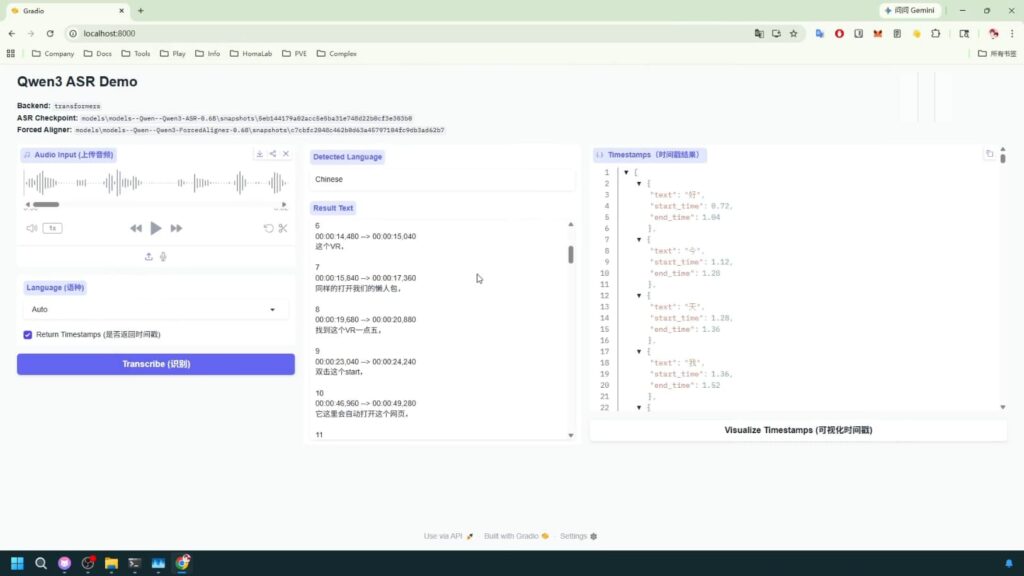
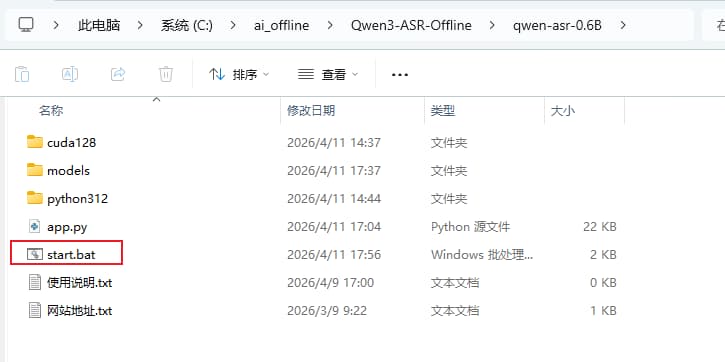
懒人包使用
双击start.bat
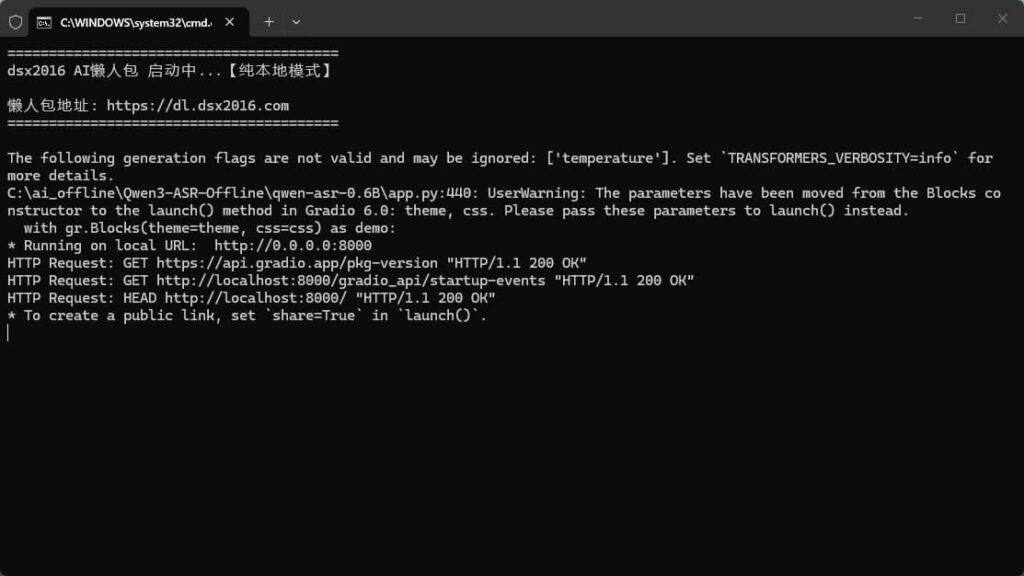
等待终端启动
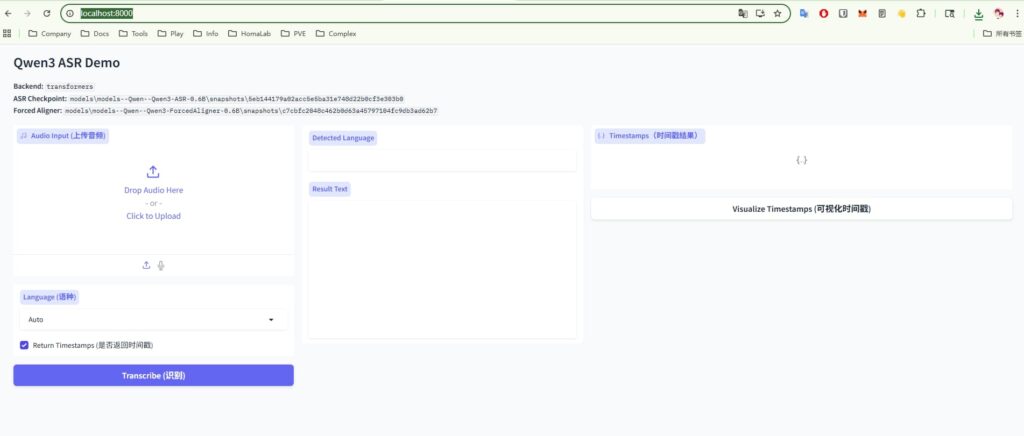
打开浏览器界面
http://localhost:8000/
上传音频开始转换
注意默认勾选时间戳,返回的内容为srt字幕
如果不勾选,返回的内容为识别的文本,不带时间节点信息
Tips
点击此处 网盘下载
官网文档描述
Qwen3-ASR 完全支持流式推理。目前,流式推理仅适用于 vLLM 后端。请注意,流式推理不支持批量推理或返回时间戳
实际测试,在windows上,我无法安装vLLM,ai提示只支持Linux
我在wsl2 docker安装Qwen3-ASR,下载了14GB镜像和一些模型,占据40Gb左右的,但是反复启动,一直报错,还没有找到解决办法,一直报显存不足
后续有空再次试试docker部署,或者在wsl2 Linux先用python环境测试一遍
看看是显存问题还是docker环境问题
Qwen3-ASR默认不支持srt字幕相关,只支持文字转录
srt文本,是由文本时间轴方法转换得来,满足一般的视频字幕需求
654字