FireRed-Image-Edit
github地址:https://github.com/FireRedTeam/FireRed-Image-Edit
🔥 FireRed-Image-Edit 项目概览
由 FireRedTeam(小红书智能创作团队)开源的通用图像编辑大模型
基于扩散模型(Diffusion)架构,专为 “按指令编辑图片” 打造。 💡 通俗理解:它是 Photoshop + Stable Diffusion 的结合体,但只需输入“自然语言”即可完成复杂编辑。
🧠 核心定位
- 类型:Instruction-driven(指令驱动)图像编辑模型
- 输入输出:
Text + Image→Edited Image - 应用场景:内容创作 / 电商设计 / AI 工具开发 / 视觉增强
✨ 六大核心能力 (Key Features)
1️⃣ 强大的图像编辑能力 🎨
- 一句话修改:无需手动抠图或分层,直接通过自然语言指令完成换背景、换衣服、添加物体等操作。
- 示例:“把这张照片改成日落场景,并给人物加墨镜”
2️⃣ 身份一致性 (SOTA 水平) 👤
- 难点攻克:在 AI 编辑领域最难保持的“人物特征不变”,它表现卓越。
- 效果:修改后,人物的脸部、五官及核心特征依然保持原样。
3️⃣ 多图融合 (Multi-image) 🧩
- 组合创作:支持输入多张图片进行智能拼接与合成。
- 典型场景:虚拟试衣(A 人物 + B 衣服 → 自动裁剪并合成试穿图)。
4️⃣ 文本与字体编辑 📝
- 精准替换:可修改图片中的文字内容,同时完美保留原有字体风格。
- 优势:解决了多数模型无法保持字体一致性的痛点。
5️⃣ 图像修复与美化 ✨
- 全能修复:老照片修复、清晰度提升(超分)。
- 人像优化:支持美颜、妆容调整及瑕疵去除。
6️⃣ 多任务统一模型 🚀
- 一机多用:无需切换不同模型,一个模型即可搞定:
- ✅ 图像编辑 & 生成
- ✅ 风格迁移
- ✅ 修复增强
- ✅ 虚拟试穿
⚙️ 硬核技术解析 (Tech Specs)
| 维度 | 详情 |
|---|---|
| 🧩 模型架构 | 基于 Diffusion Transformer,支持文本/图像多模态条件融合。 |
| 📊 训练规模 | 约 16 亿 (1.6B) 样本: • 文本 – 图像对 • 专业图像编辑对 |
| 🧪 训练流程 | 预训练 (Pretrain) → 监督微调 (SFT) → 强化学习优化 (RL) |
| ⚡ 性能优化 | • 支持模型蒸馏与量化 • 推理速度:高端 GPU 下约 4.5 秒/张 |
🏆 性能表现 & 生态
- 基准测试:在 ImgEdit / GEdit 等权威榜单中达到或超越 SOTA (State-of-the-Art)。
- 人类评测:指令理解更精准,图像一致性显著优于竞品。
- 工程生态:
- 📦 开源协议:Apache-2.0(可本地部署)
- 🔌 工具支持:原生支持 ComfyUI 节点、LoRA 微调扩展。
📦 GitHub 仓库通常包含
- 🛠️ 推理代码 (Inference Scripts)
- ⚙️ 模型加载与配置方式
- 🎨 ComfyUI 专用节点
- 💬 示例 Prompt 库
- 🔧 LoRA 扩展包
👥 适合人群
| 角色 | 应用场景 |
|---|---|
| 👨💻 AI 开发者 | 构建修图、换装、设计类 AI 产品 |
| 📸 内容创作者 | 快速生成电商海报、营销素材 |
| 🔬 研究人员 | Diffusion + Editing 算法研究 |
⚠️ 局限与注意点
- 📏 分辨率限制:超高分辨率支持仍需优化(建议配合放大插件)。
- 😐 极端角度:人脸在极端角度变化下的一致性仍有挑战。
- 💾 显存需求:完整版模型需要较高的 GPU 显存。
🧭 一句话总结
FireRed-Image-Edit = 当前最强开源“图像编辑型大模型”之一
🔑 核心卖点:“一句话改图” + “高身份一致性” + “多图融合能力”
懒人包使用
双击run_nvidia_gpu.bat
终端启动
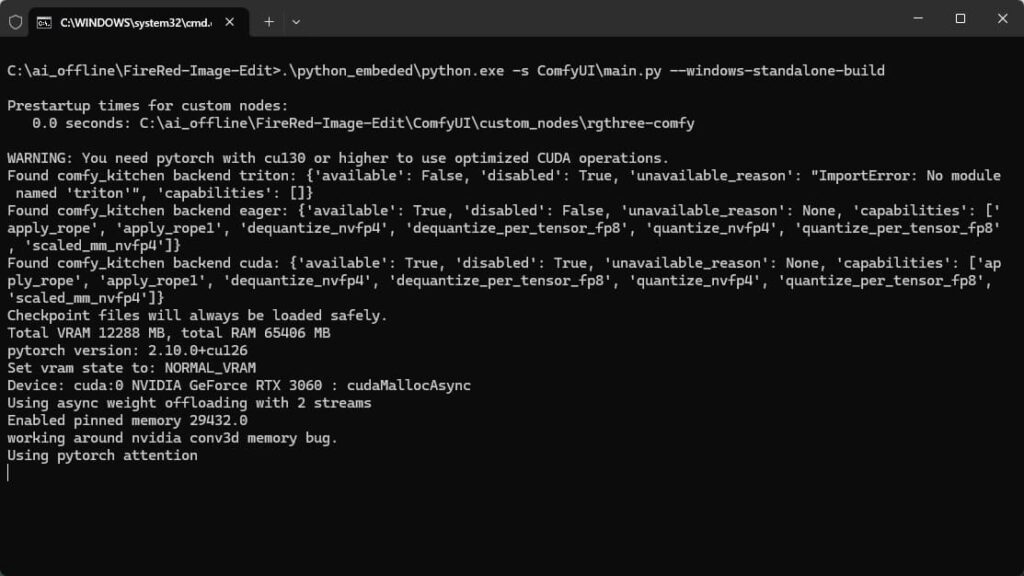
会自动打开浏览器
选择人物图片,点击run,就可以获取对应的衣物图片
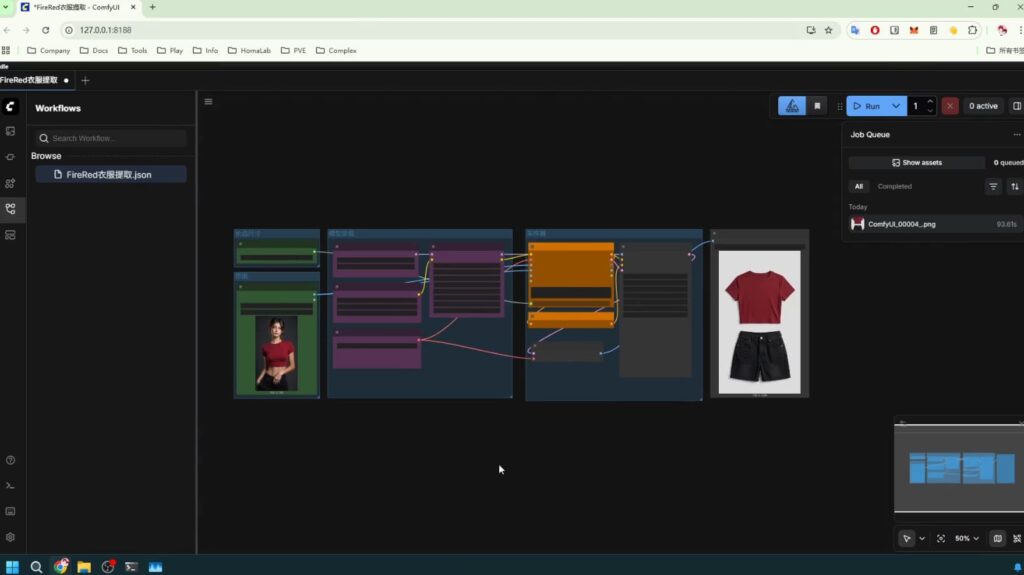
Tips
点击此处 网盘下载
如果网页里面没有提取衣物工作流,可以把懒人包里面的文件(FireRed衣服提取.json),直接拖拽到网页,就有了工作流,ctrl+s保存
如果点击run报错,提示找不到对应的模型,报红框错误(需要手动点击模型,选择模型)
如果遇到红框问题,可以查看本文视频
1,572字