Qwen3-ASR
github地址:https://github.com/QwenLM/Qwen3-ASR
📦 Qwen3-ASR:新一代开源语音识别系统
Qwen3-ASR 是阿里通义团队推出的开源语音识别(ASR)模型及工具链,旨在将语音高效转化为文本(Speech-to-Text)。
👉 一句话定位:Whisper 的“现代化替代方案”,更现代、支持流式处理,且具备工程级落地能力。
🧠 核心定位与功能
属于 Qwen 体系中的专用语音模块,专注于以下三大任务:
- 🔊 语音识别 (ASR):高精度转写。
- 🌍 语言识别:自动检测输入语种(无需手动指定)。
- ⏱️ 时间戳对齐:配合
aligner实现精准的时间轴定位。
🎯 适用场景
| 场景类型 | 具体应用 |
|---|---|
| 实时交互 | AI 语音助手、实时会议记录 |
| 内容生产 | 视频字幕生成、播客转写 |
| 数据分析 | 语音情感分析、声纹识别系统 |
🚀 六大核心亮点 (Key Features)
1️⃣ 双模驱动:流式 + 非流式
一套模型,两种模式,灵活应对不同需求。
- ✅ 实时 Streaming:边说边出字(低延迟)。
- ✅ 批量离线:处理长音频或录音文件。
2️⃣ 多语言与方言支持
- 🌐 覆盖范围:支持 52 种 语言及方言。
- 🤖 自动识别:无需预设,模型自动判断输入语种。
3️⃣ 双版本模型矩阵
针对不同性能需求提供差异化选择:
| 模型版本 | 参数量 | 特点描述 | 适用场景 |
|---|---|---|---|
| 0.6B | 轻量级 | ⚡ 高并发、极速响应 | 实时系统部署、边缘设备 |
| 1.7B | 标准级 | 🎯 SOTA 级精度 | 对准确率要求极高的场景 |
💡 注:0.6B 版本在保持高精度的同时,极大降低了计算资源消耗。
4️⃣ 强鲁棒性 (Robustness)
在复杂现实场景中表现优异,显著优于传统模型:
- 🎙️ 噪音环境:抗噪能力强。
- ⚡ 快语速:流畅处理快速对话。
- 🗣️ 方言识别:对非标准发音有良好适应性。
- 🎵 唱歌/混音:能处理带旋律的语音输入。
5️⃣ 精准时间戳与对齐
配套模型:Qwen3-ForcedAligner
- 🔗 功能:实现单词级时间戳定位。
- ✨ 价值:支持高精度字幕生成,完美解决“音画不同步”痛点。
6️⃣ 工程级性能优势
专为实时系统优化,具备极低的延迟和极高的吞吐:
- ⚡ 首字延迟 (TTFT):≈ 92ms(极速响应)。
- 📈 高并发吞吐:轻松支撑多路语音流。
🧱 项目架构与组件
GitHub 仓库不仅提供模型,更是一个完整的推理框架 + Demo UI生态:
- 🔌 Python 接口:标准化的推理调用方式。
- 🛠️ CLI 工具:命令行交互(如
qwen_asr.cli.demo)。 - 🖥️ Demo UI:基于 Gradio 的可视化演示界面。
⚔️ 竞品对比:Qwen3-ASR vs. Whisper 系列
| 特性 | Whisper (老一代) | WhisperX (Whisper + 对齐增强) | Qwen3-ASR (新一代) |
|---|---|---|---|
| 架构定位 | 基础 ASR 模型 | 基础模型 + 后处理对齐 | 端到端原生支持 |
| 流式能力 | ❌ 较弱/需额外配置 | ⚠️ 依赖外部逻辑 | ✅ 原生支持 (边说边出) |
| 延迟性能 | 🐢 较高 | 🐢 中等 | 🚀 极低 (92ms TTFT) |
| 多语言覆盖 | 广泛 | 广泛 | 🌏 52+ 语种/方言 |
💡 总结与下一步建议
🧠 核心总结: Qwen3-ASR 是一个支持实时流式、具备强多语言鲁棒性且工程可落地的开源语音识别系统,代表了 2026 年的主流技术方向。
🚀 如果你已跑通 Demo,下一步可以做什么?
- 构建 API 服务:封装为 RESTful API 或 WebSocket 接口,供前端调用。
- 实时麦克风接入:开发桌面/移动端应用,实现“说话即转写”。
- 字幕系统开发:结合
ForcedAligner,自动化生成 SRT/VTT 字幕文件。 - AI Agent 集成:将语音输入作为大模型 Agent 的感知入口,打造全语音交互体验。
懒人包使用
点击start.bat
等待终端启动
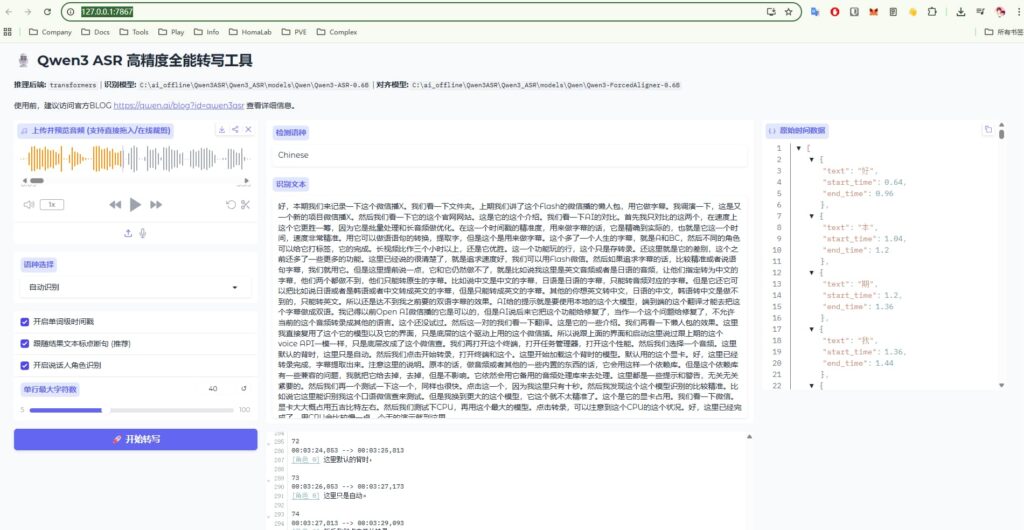
打开地址http://127.0.0.1:7867/
上传音频,点击转录
Tips
点击此处 网盘下载
这个版本为Qwen3-ASR 0.6B版本,网上找到懒人包
1.7B的版本更加精准,但是显存占用较大,目前0.6B测试显存大约6GB占用
后续酌情补充1.7B的Qwen3-ASR版本
特别说明,Qwen3-ASR支持流式处理,但本文懒人包暂未接入,后续再看
1,624字